
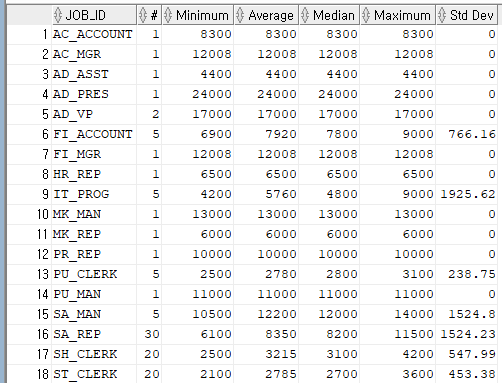
각각 "__" 으로 보기쉽게 이름을 지정해줬고
employees 테이블로 부터
각각의 정보를 불러 내왔다.
job_id로 그룹지정을 해서 job_id 별로 구분해서 볼 수 있게 만들었다
각 job_id 별 최소값, 평균값, 최댓값을 구해줬다.
std dev 표준편차를 구하는 함수를 이용했고 round를 이용하여 소수점 2번째 자리까지 표현했다.
-- 특정 필드에 대해서 통계를 낼 때
select manager_id, count(*) "Number of Reports" from employees
group by manager_id order by manager_id;
-- 부서별 월급의 합
select department_id, sum(salary*12) from employees
group by department_id
having sum(salary*12) >= 1000000;
-- 업무에 따른 월급통계
select job_id, count(*) "#", min(salary) "Minimum", avg(salary) "Average", median(salary) "Median",
max(salary) "Maximum", round(stddev(salary),2) "Std Dev" from employees
group by job_id;
--슬라이드 12, 13, 14번 문제
--91. 학과의 수를 검색
SELECT COUNT(DISTINCT STU_DEPT) "학과의 수" FROM STUDENT;
SELECT COUNT(*) FROM (SELECT STU_DEPT, COUNT(*) FROM STUDENT GROUP BY STU_DEPT);
--92. 학생들의 성씨의 수
SELECT COUNT(DISTINCT SUBSTR(STU_NAME,1,1)) "성씨의 수" FROM STUDENT;
--93. 학생테이블의 레코드의 수를 검색
SELECT COUNT(*) FROM STUDENT;
--94. entrol테이블의 레코드의 수를 검색
SELECT COUNT(*) FROM ENROL;
--95. 학과별 학생들의 인원수를 검색
SELECT STU_DEPT, COUNT(*) FROM STUDENT GROUP BY STU_DEPT;
--96. 학과별 학생들의 인원수를 인원수가 많은 순으로 검색
SELECT STU_DEPT, COUNT(*) FROM STUDENT GROUP BY STU_DEPT ORDER BY COUNT(*) DESC;
--97. 학년별 학생들의 인원수를 검색
select stu_grade, count(stu_grade) "인원수" from student
group by stu_grade;
--98. 학년별 학생들의 인원수가 많은 순으로 검색
select stu_grade "학년", count(*) "인원수" from student
group by stu_grade order by count(*) desc;
--99. 학과별 학생들의 평균신장을 검색
SELECT STU_DEPT, ROUND(AVG(stu_height),2) FROM STUDENT GROUP BY stu_dept ;
--100. 학과별 학생들의 체중의 표준편차를 검색 (STDDEV)
select stu_dept, round(stddev(stu_weight),2) from student
group by stu_dept;
--102. 학과별 학년별 학생들의 평균 체중
select stu_dept, stu_grade, avg(stu_weight) from student
group by stu_dept, stu_grade order by stu_dept;
--103. 학과별 학년별 학생들의 학번의 max와 min값을 검색
SELECT stu_dept, stu_grade, MAX(stu_no) MAX, MIN(stu_no) MIN
FROM STUDENT
GROUP BY stu_dept,stu_grade
ORDER BY stu_dept, stu_grade;
--104. 학과별 학생들의 인원수를 인원수가 많은 순으로 검색
select stu_dept, count(*) from student group by stu_dept order by COUNT(*) desc;
--105. 학과별 학생들의 평균신장을 평균 신장 순으로 검색
SELECT STU_DEPT, AVG(STU_WEIGHT) FROM STUDENT GROUP BY STU_DEPT ORDER BY AVG(STU_WEIGHT);
--106. 학과별 학년별 학생들의 평균체중을 평균 체중이 많은 순으로 검색
SELECT STU_DEPT, STU_GRADE, ROUND(AVG(STU_WEIGHT),1) FROM STUDENT
GROUP BY STU_DEPT, STU_GRADE ORDER BY AVG(STU_WEIGHT) DESC;
--107. 학과별 학생들의 평균신장을 평균 신장이 높은 순으로 검색
select STU_DEPT, round(avg(STU_HEIGHT)) from STUDENT
group by STU_DEPT order by round(avg(STU_HEIGHT)) desc;
--108. 학과별 학생들의 평균신장이 170 이상인 학과를 평균 신장이 낮은 순으로 검색 (having)
SELECT stu_dept, COUNT(*), ROUND(AVG(stu_height)) FROM student
HAVING AVG(stu_height) >= 170 group by stu_dept ORDER BY AVG(stu_height);
--라이브러리 DB ==> 시각화
--Number of transactions by year? 년도별 거래수?
select transaction_year, count(*) from transaction group by transaction_year;
--NVL 함수 (21 슬라이드)
--77. 신장열의 값이 널인 학생의 경우 ‘미기록'으로 기록
select nvl(to_char(stu_height), '미기록') FROM STUDENT;
--78. 신장과 체중을 합한 값을 학번, 이름과 함께 검색 (nvl)
select stu_no, stu_name, nvl2(stu_height, stu_height+stu_weight, stu_weight) from student;
SELECT STU_NO, STU_NAME, NVL(STU_HEIGHT + STU_WEIGHT, STU_WEIGHT) FROM STUDENT;
--79. 신장에서 체중을 뺀값을 학번, 이름과 함께 검색 (nvl)
select stu_no, stu_name, nvl2(stu_height, stu_height-stu_weight, stu_weight) from student;
--80. 신장이 null인 경우 ‘입력 요망’으로 바꾸어 학번, 이름을 검색
select stu_no, stu_name, nvl(to_char(stu_height), '입력 요망') from student;
--현재의 시각을 출력하시요. (SYSDATE 이용하여.. 시.. 분.. 초 형식으로)
select sysdate from dual;
select systimestamp from dual;
SELECT to_char(sysdate,'hh24/mi/ss') from dual;
SELECT TO_CHAR(SYSDATE,'HH"시" MI"분" SS"초"') FROM DUAL;
SELECT TO_CHAR(sysdate, 'yyyy/mm/dd HH:MI:SS AM') FROM DUAL;
--오늘이 올해의 몇번째 날인지 출력하시오. (DDD 이용하여 …일)
select to_char(sysdate,'ddd') from dual;
--오늘의 요일을 출력하시요.
select to_char(sysdate,'day') from dual;
-- 테이블 2개 합치는 코드
create table CM as (select t.transaction_year "연도", b.genre "장르", count(*) "거래량"
from transaction t, books b
where t.book_id = b.book_id
group by t.transaction_year, b.genre);
select * from cm;
create table max_tab as (select 연도, max(거래량) max_transaction from CM group by 연도);
select * from max_tab order by 연도;
-- 테이블 위아래로 합치기
select * from table1
union
select * from table2;
select * from cm, max_tab where cm. 연도 = max_tab.연도 and 거래량 = max_transaction order by cm.연도;
-- 특정 필드에 대해서 통계를 낼 때
select manager_id, count(*) "Number of Reports" from employees
group by manager_id order by manager_id;
-- 부서별 월급의 합
select department_id, sum(salary*12) from employees
group by department_id
having sum(salary*12) >= 1000000;
-- 업무에 따른 월급통계
select job_id, count(*) "#", min(salary) "Minimum", avg(salary) "Average", median(salary) "Median",
max(salary) "Maximum", round(stddev(salary),2) "Std Dev" from employees
group by job_id;
--슬라이드 12, 13, 14번 문제
--91. 학과의 수를 검색
SELECT COUNT(DISTINCT STU_DEPT) "학과의 수" FROM STUDENT;
SELECT COUNT(*) FROM (SELECT STU_DEPT, COUNT(*) FROM STUDENT GROUP BY STU_DEPT);
--92. 학생들의 성씨의 수
SELECT COUNT(DISTINCT SUBSTR(STU_NAME,1,1)) "성씨의 수" FROM STUDENT;
--93. 학생테이블의 레코드의 수를 검색
SELECT COUNT(*) FROM STUDENT;
--94. entrol테이블의 레코드의 수를 검색
SELECT COUNT(*) FROM ENROL;
--95. 학과별 학생들의 인원수를 검색
SELECT STU_DEPT, COUNT(*) FROM STUDENT GROUP BY STU_DEPT;
--96. 학과별 학생들의 인원수를 인원수가 많은 순으로 검색
SELECT STU_DEPT, COUNT(*) FROM STUDENT GROUP BY STU_DEPT ORDER BY COUNT(*) DESC;
--97. 학년별 학생들의 인원수를 검색
select stu_grade, count(stu_grade) "인원수" from student
group by stu_grade;
--98. 학년별 학생들의 인원수가 많은 순으로 검색
select stu_grade "학년", count(*) "인원 수" from student
group by stu_grade order by count(*) desc;
--99. 학과별 학생들의 평균신장을 검색
SELECT STU_DEPT, ROUND(AVG(stu_height),2) FROM STUDENT GROUP BY stu_dept ;
--100. 학과별 학생들의 체중의 표준편차를 검색 (STDDEV)
select stu_dept, round(stddev(stu_weight),2) from student
group by stu_dept;
--102. 학과별 학년별 학생들의 평균체중
select stu_dept, stu_grade, avg(stu_weight) from student
group by stu_dept, stu_grade order by stu_dept;
--103. 학과별 학년별 학생들의 학번의 max와 min값을 검색
SELECT stu_dept, stu_grade, MAX(stu_no) MAX, MIN(stu_no) MIN
FROM STUDENT
GROUP BY stu_dept,stu_grade
ORDER BY stu_dept, stu_grade;
--104. 학과별 학생들의 인원수를 인원수가 많은 순으로 검색
select stu_dept, count(*) from student group by stu_dept order by COUNT(*) desc;
--105. 학과별 학생들의 평균신장을 평균신장 순으로 검색
SELECT STU_DEPT, AVG(STU_WEIGHT) FROM STUDENT GROUP BY STU_DEPT ORDER BY AVG(STU_WEIGHT);
--106. 학과별 학년별 학생들의 평균체중을 평균체중이 많은 순으로 검색
SELECT STU_DEPT, STU_GRADE, ROUND(AVG(STU_WEIGHT),1) FROM STUDENT
GROUP BY STU_DEPT, STU_GRADE ORDER BY AVG(STU_WEIGHT) DESC;
--107. 학과별 학생들의 평균신장을 평균신장이 높은 순으로 검색
select STU_DEPT, round(avg(STU_HEIGHT)) from STUDENT
group by STU_DEPT order by round(avg(STU_HEIGHT)) desc;
--108. 학과별 학생들의 평균신장이 170이상인 학과를 평균신장이 낮은 순으로 검색 (having)
SELECT stu_dept, COUNT(*), ROUND(AVG(stu_height)) FROM student
HAVING AVG(stu_height) >= 170 group by stu_dept ORDER BY AVG(stu_height);
--라이브러리 DB ==> 시각화
--Number of transactions by year? 년도별 거래수?
select transaction_year, count(*) from transaction group by transaction_year;
--NVL 함수 (21 슬라이드)
--77. 신장열의 값이 널인 학생의 경우 ‘미기록'으로 기록
select nvl(to_char(stu_height), '미기록') FROM STUDENT;
--78. 신장과 체중을 합한 값을 학번, 이름과 함께 검색 (nvl)
select stu_no, stu_name, nvl2(stu_height,stu_height+stu_weight, stu_weight) from student;
SELECT STU_NO, STU_NAME, NVL(STU_HEIGHT + STU_WEIGHT, STU_WEIGHT) FROM STUDENT;
--79. 신장에서 체중을 뺀값을 학번, 이름과 함께 검색 (nvl)
select stu_no, stu_name, nvl2(stu_height, stu_height-stu_weight, stu_weight) from student;
--80. 신장이 null인 경우 ‘입력요망’으로 바꾸어 학번, 이름을 검색
select stu_no, stu_name, nvl(to_char(stu_height), '입력요망') from student;
--현재의 시각을 출력하시요. (SYSDATE이용하여 ..시..분..초 형식으로)
select sysdate from dual;
select systimestamp from dual;
SELECT to_char(sysdate,'hh24/mi/ss') from dual;
SELECT TO_CHAR(SYSDATE,'HH"시" MI"분" SS"초"') FROM DUAL;
SELECT TO_CHAR(sysdate, 'yyyy/mm/dd HH:MI:SS AM') FROM DUAL;
--오늘이 올해의 몇번째 날인지 출력하시요. (DDD이용하여 …일)
select to_char(sysdate,'ddd') from dual;
--오늘의 요일을 출력하시요.
select to_char(sysdate,'day') from dual;
-- 테이블 2개 합치는 코드
create table CM as (select t.transaction_year "연도", b.genre "장르", count(*) "거래량"
from transaction t, books b
where t.book_id = b.book_id
group by t.transaction_year, b.genre);
select * from cm;
create table max_tab as (select 연도, max(거래량) max_transaction from CM group by 연도);
select * from max_tab order by 연도;
-- 테이블 위아래로 합치기
select * from table1
union
select * from table2;
select * from cm, max_tab where cm.연도 = max_tab.연도 and 거래량 = max_transaction order by cm.연도;
'Oracle' 카테고리의 다른 글
| [Oracle VM] CentOs 환경 NAT 서버 구축해서 내부망 접근하기 (2) | 2023.05.26 |
|---|---|
| [Oracle] SYNTAX FOR SQL (Join / Join on / Natural Join / Inner join / non equi join / Self Join /etc..) (0) | 2022.10.20 |
| [Oracle] 테이블에 데이터 Import 후 원하는 정보 추출해보기.(group by) (0) | 2022.10.19 |
| [Oracle] SELECT문을 이용한 응용연습 해보기 (0) | 2022.10.18 |
| [Oracle] 테이블 생성 후 DATA 자료 INSERT 하기 (0) | 2022.10.18 |




댓글