공공데이터 포털에 있는 자료를 활용하여 전국 신규 민간 아파트 분양 가격 데이터를 분석해보려고 한다.

https://www.data.go.kr/data/15061057/fileData.do
주택도시보증공사_전국 신규 민간아파트 분양가격 동향_20211231
주택분양보증을 받아 분양한 전체 민간 신규아파트 분양가격 동향으로 지역별, 면적별 분양가격 등의 자료를 제공합니다.<br/>해당 데이터는 주택도시보증공사 홈페이지 및 통계청 KOSIS에서도
www.data.go.kr
데이터 파일은 공공데이터 포털에 2021년 12월 31일 자료로 주택도시보증공사에서 제공한 자료를 활용하였다.
1. 전국 신규 민간아파트 분양가격 동향 데이터 읽어오기
df = pd.read_csv('./data/전국신규민간아파트분양가격동향_20211231.csv', encoding='cp949')
df데이터를 df로 받아주고 csv 파일을 자신의 컴퓨터 환경에 맞게 저장경로를 파악하여 데이터를 불러오도록 하자.
데이터인코딩이 필요하여 별도의 encoding 코드를 넣어주었다. csv파일이니 pd.read_csv로 읽어왔다.
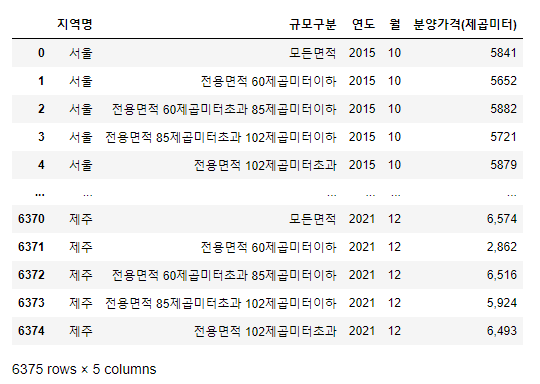
총 6375행과 5개의 컬럼으로 이루어져 있는 파일이다. (df.shape로도 알 수 있음)
위에 상단으로부터 데이터는 head를 사용하고 밑에서부터 데이터를 살펴 보려면 tail을 사용해주면된다.
ex) df.head() // df.tail()
데이터 분석을 하기 전에는 데이터를 둘러보는게 중요한데 결측치는 없는지 만약 있다면 원하는 목표를 위하여 어떤식으로 그 결측치를 처리해 줄 지 잘 생각해보고 데이터를 목적에 맞게 잘 다듬어 줘야한다.
df.dtypes
df.isnull().sum()
df.describe()데이터 타입과, 결측치 확인, 통계량을 확인해 본다.



데이터를 둘러보니 분양가격에 해당하는 컬럼에 484개에 해당하는 데이터 결측치 null 즉 nan 값이 존재함을 알 수 있다.
그래서 분양가격(제곱미터) null 값에 대한 정보만을 뽑아보았다.
결측치에 해당하는 데이터만 뽑아보는 코드는 다음과 같다.
df.loc[df['분양가격(제곱미터)'].isnull()]필자는 loc을 이용하여 df 데이터에 해당 컬럼의 null값을 갖고 있는 데이터를 뽑아봤다.

그리고 추후에 계산을 위해 결측치 값을 0으로 대체해주었다.
df = df.fillna(0)
기존 결측치 값들이 모두 0으로 채워졌다.
또한 분양가격 타입이 확인해보면 object 로 되어있기 때문에 int로 바꿔주는것이 올바른 방법이라고 판단해서 바꿔주기로 했다. astype을 이용하여 바꿔주자
df['분양가격(제곱미터)'].astype(int)올바르게 작성했지만 오류를 만났다.

오류 코드를 확인해보면 ' ' 이렇게 데이터에 빈공간이 있는 모습이다
빈공간을 제거 해주도록 해야겠다.
df.loc[df['분양가격(제곱미터)']==' ']이렇게 지금 빈공간이 있는 데이터를 추려보았다.

이렇게 빈공간으로 나와있는 데이터들도 모두 0으로 바꿔주도록하겠다.
df.loc[df['분양가격(제곱미터)'] == ' ', '분양가격(제곱미터)'] = 0
df.loc[df['분양가격(제곱미터)']==' ']빈공간으로 남겨져 있는 아이들도 모두 0으로 대체되었다.
하지만.. 또다시 마주한 에러..
어떤 값은 숫자에 콤마 , 가 있고 어떤 값은 없다.
그래서 통일성 있게 , 를 모두 제거해주기로했다
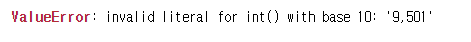
문자열의 경우 str을 꼭 붙여 치환 해줘야 잘 작동한다.
df['분양가격(제곱미터)'] = df['분양가격(제곱미터)'].str.replace(',', '')

이제 분양가격 컬럼 데이터 타입을 int로 바꿔보자!! 드디어!!
df['분양가격(제곱미터)'].astype(int)하지만 다시 발생한 Nan값이 있다는 오류
다시한번 nan값 결측치를 제거해주자.

df['분양가격(제곱미터)'] = df['분양가격(제곱미터)'].fillna(0)
분양가격 컬럼의 결측치를 다시 0으로 치환 해주었다.
df['분양가격(제곱미터)'].astype(int)
드디어 분양가격의 데이터 타입이 int로 변경되었다.!!

결측치도 모두 처리해주고 숫자형태이지만 object data type 이였던것도 int 형식으로 잘 바꿔주었다.
이제 규모구분 컬럼 내의 데이터를 조금 더 가다듬으려고 한다.

규모구분 컬럼 내 들어가있는 전용면적을 별도로 컬럼을 만들어 빼주도록하고, 규모구분 컬럼은 삭제해주겠다.
분양가격도 정리된 데이터를 보게된다면 알 수 있게
분양가격(제곱미터)'*3.3인 평당분양가격 컬럼을 따로 생성하여 데이터를 만들어보겠다.
그 후 보기 쉬운 컬럼 순서대로 컬럼 정렬을 실시하겠다.
df['규모구분'].value_counts()
규모구분 컬럼을 보면 보기 어렵게 되어있다.
제곱미터 단위를 글자가 아닌 전용 단위로 변경해주겠다.
df['규모구분']=df['규모구분'].str.replace('제곱미터', 'm²')
전용면적이라는 말이 불필요하게 들어가 있어 차라리 컬럼 자체로 빼주고 전용면적에 대한 내용만 위치 할 수 있게 변경해야겠다.
df['규모구분']=df['규모구분'].str.replace('전용면적', '')전용면적이라는 단어 삭제!

df = df.rename(columns={'규모구분':'전용면적'})

규모구분 컬럼 이름명을 전용면적으로 바꾸어주었다. 데이터 내 불필요한 단어인 '전용면적'이 계속 반복되어 이렇게 컬럼 명으로 빼주니 아주 깔끔해진 모습이다!!
이제 비워져있는 분양가격에 대한 데이터를 만들어보자!
df['평당분양가격'] = df['분양가격(제곱미터)']*3.3
df.head()평당분양가격이라는 새로운 컬럼을 추가해 주면서 다듬어진 분양가격 컬럼에 3.3을 곱한값을 데이터로 넣어주겠다.

df = df[['지역명', '연도', '월', '분양가격(제곱미터)', '평당분양가격', '전용면적']]
df.head()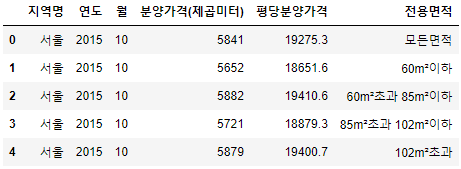
사람들이 보기 쉬운 순서대로 컬럼 순서를 변경해주었다.
df_area = df.groupby('지역명').mean().reset_index()
df_area = df_area.sort_values(by=['평당분양가격'], ascending=False)처음엔 지역명으로 그룹바이를 하여 지역별로 평당분양가격 평균값을 구했고
그 후엔 평당분양가격으로 내림차순하여 정렬하였다.
또한 새롭게 인덱스를 붙여 주었다.
지역별 평당분양가격에 대해 한눈에 알아보기 위해 시각화 해보았다.
import seaborn as sns
import matplotlib.pyplot as pltplt.figure(figsize=(10,5))
sns.barplot(x = '지역명' , y = '평당분양가격', data=df_area)
이 데이터를 살펴 보았을때 전국에서 서울이 압도적인 가격으로 평당분양가격이 형성되어있다는 사실을 알 수 있다.
sns.barplot(x = '연도' , y = '평당분양가격', data=df)

또한, 연도별로 매해 꾸준히 평당분양가격이 상승하고 있는 모습인 사실을 알 수 있다.
'Pandas' 카테고리의 다른 글
| [Jupyter Notebook] 주피터노트북 목차 활성화 (2) | 2022.11.07 |
|---|---|
| [데이터 분석] 귀무가설, 대립가설, 기대 개수, 검정 통계량에 대하여 (2) | 2022.11.03 |
| [Pandas] Numpy 배열 인덱싱/슬라이싱 (0) | 2022.11.02 |
| [Pandas] Numpy - matplotlib, seaborn를 이용한 자료 시각화 (2) | 2022.11.01 |
| [Pandas] Numpy - np.zeros, ones, full, eye, random 알아보기 (0) | 2022.11.01 |




댓글