확인하고자 하는 사항을 가설로 세우고, 이 가설이 실제로 맞는지를 검증하는 과정이
바로 통계분석 과정이다. 통계분석 과정에서 쓰이는 이해하기 어려웠던 것들을 정리해 보도록 하겠습니다.
귀무가설 (Null Hypothesis, H0)
귀무가설, 입에 붙지 않는 단어이다.
예를 들어 한 영화관에서, 상영하는 영화의 장르가 간식류 구매에 영향을 미치는지 분석하여 상영 영화 시간에 맞게 스낵을 알맞은 재고로 맞춰두고 싶어 한다면 데이터 분석을 할 줄 아는 당신이라면 조언해 줄 수 있을 것이다.
A : "영화 장르가 간식류 구매에 영향을 줄 거 같아?"
B : "아니, 다 비슷하겠지"
A : "아니야 근데 내 생각엔 사람들이 공포영화 보러 들어갈 때 더 팝콘을 많이 구매하는 거 같아"
B : "느낌일 뿐이지 어떻게 그래 장르랑 간식 사는 건 아무 관계없을 거 같아."
여기서 B의 주장은
가설로
' 영화 장르와 관람객들의 간식류 구입 여부 사이에는 관련성이 없을 것이다'라고
그래서 600명의 관객을 추출하여 장르별 간식류를 구매했는지에 대한 조사를 하고
조사 결과로 아래와 같은 데이터를 얻을 수 있었다고 치자.
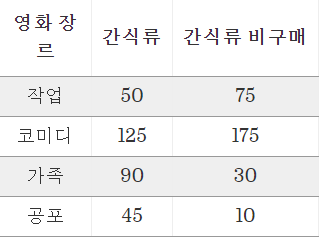
카이제곱 독립성 검정을 통해 상관관계를 알아보고자 할 때,
우리는 데이터를 분석하기 위해 기대 개수를 가장 먼저 구해야 한다.
기대 개수를 알기 위해선
각 영화-간식류 조합에 대한 기대 개수를 구하려면 먼저 아래 나온 행과 열 합계가 필요하다.
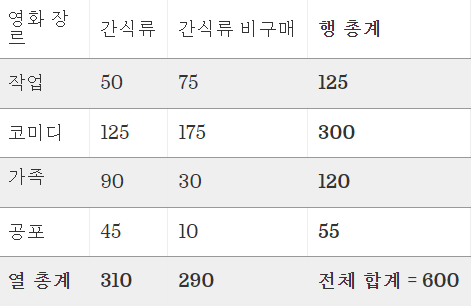
그러니까, 가설을 세우고 나면, 통계적인 유의성(Significance)과 p value 값이 등장하게 되는데, 예를 들어 실험을 통해 얻은 그룹 간의 차이가 무작위로 발생할 수 있는 합리적인 수준보다 더 극단적으로 다르다면, 두 그룹의 차이가 우연히 나온 것은 아니지 않나? 하는 접근을 하게 되는데, 그때 판단 기준이 유의 수준과 p value라는 것입니다. 결과적으로, 가설검정은 관측 결과가 우연에 의한 것인지를 판별하여, 우연한 사건을 유의미 있는 데이터로 오해하거나 속지 않도록 하기 위한 방법이라고 볼 수 있다.
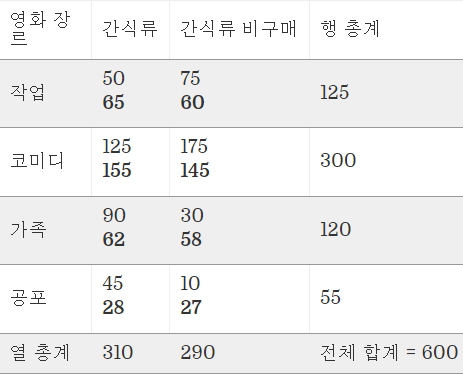
굵은 글씨로 표시된 것이 해당 셀, 즉 해당 데이터에 대한 기대 개수 값이다.
즉, 기대 개수 값은 행과 열 합계를 기준으로 한다.
행 합계에 열 합계를 곱한 결과를 전체 합계로 나눈다.
아래와 같은 계산식을 참조할 수 있겠다.
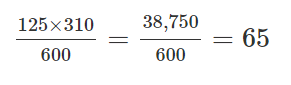
각각의 기대 개수를 구했다면 이제 검정 통계량을 구해야 합니다.
검정 통계량이란, 관측치 값에서 기대 개수 값을 뺀 후 그 차이 값을 제곱한 값을 기댓값으로 나눈 값을 모두 더한 값이다!
다음과 같은 계산 결과를 얻을 수 있고 각각 셀(데이터)에서 나온 값들을 모두 더하면 다음과 같다.
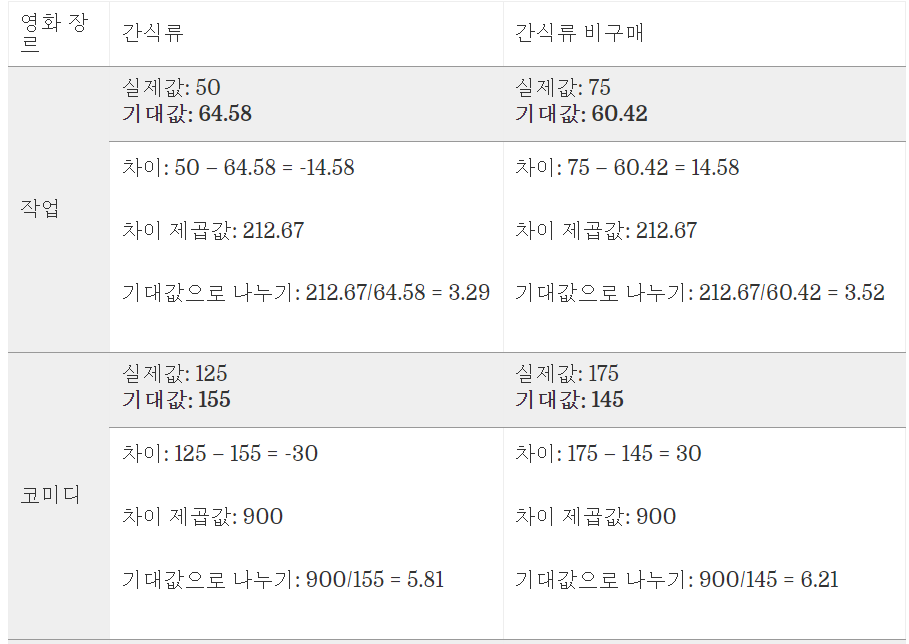
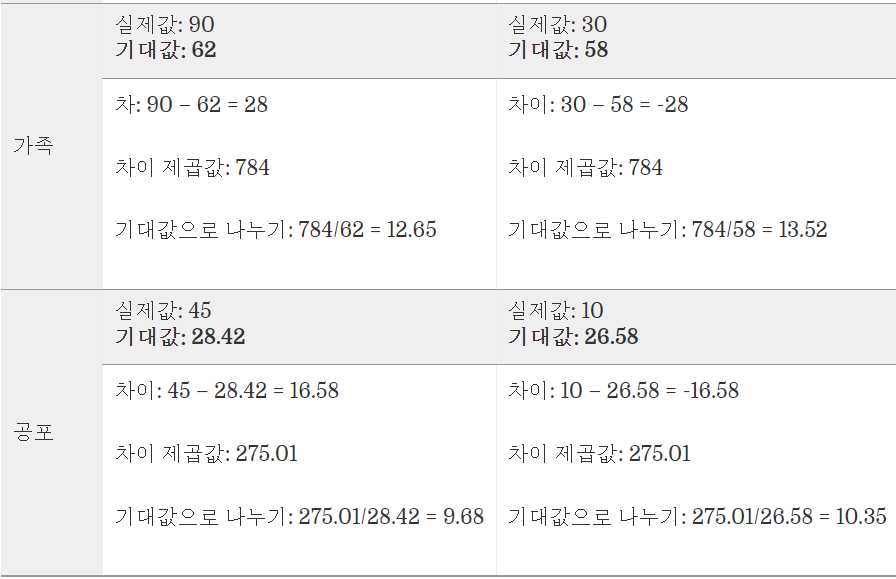
다음과 같은 계산 결과를 얻을 수 있고 각각 셀(데이터)에서 나온 값들을 모두 더하면 다음과 같다.
3.29 + 3.52 + 5.81 + 6.21 + 12.65 + 13.52 + 9.68 + 10.35 = 65.03
이 값이 바로 우리가 구하려 했던 검정 통계량이다.
여기서 제곱 연산이 들어가는 이유는 실제 관측치 값이 기대값 보다 많을 경우 음수가 나오기 때문에 이를 계산해주기 위해서 제곱을 하는 것이다.
자유도는 사용되는 행과 열의 수에 따라 결정된다.
자유도(df)의 계산식은 다음과 같다.
행개수에서 1을 빼고 열 갯수에서 1을 뺀 값을 곱해준다
이 계산식에서 r은 분할표의 행 개수이고, c는 분할표의 열 개수입니다.
예제에서는 영화 장르를 행으로, 간식류 구입 여부를 열로 각각 사용하여 다음과 같은 계산식이 나옵니다.
df=(4−1)×(2−1)=3×1=3
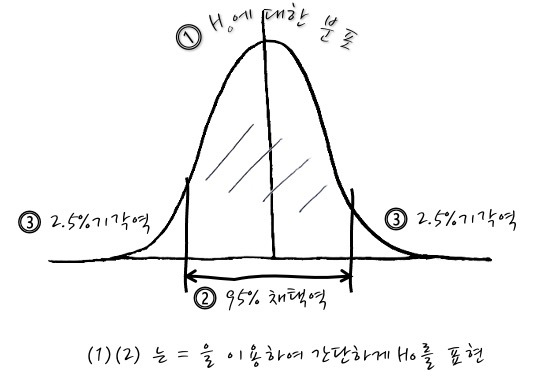
α = 0.05, 자유도 3에 해당하는 카이제곱 값은 7.815입니다.
카이제곱 값은 이미 계산되어 있는 표를 찾아 해당 값을 찾아주도록 해야 한다.
여기서 5%의 위험을 감수하기로 결정했다. 통계량 측면에서 유의 수준 α를 0.05로 설정한다.
검정 통계량(65.03) 값을 카이제곱 값과 비교합니다.
65.03 > 7.815
카이제곱 값 보다 검정 통계량 값이 높다.
65.03 > 7.815이므로 영화 장르와 간식류 구매가 독립적이라는 가정을 기각합니다.
즉, 귀무가설인 영화 장르에 따라 간식류 구매가 독립적이라는(연관이 없다) 가정을 기각할 수 있다.
그 영화 장르와 간식류 구매 사이에 상관성이 존재한다는 결론을 내린다. (독립적이지 않다)
대립가설 (Alternative Hypothesis, H1)
이에 따라, 기존 귀무가설은 기각되고
그에 반하는 대립 가설 '영화 장르와 간식류 구매 사이에 연관성이 있다' 이 채택되게 되는 것이다.
다음번엔 양측검정에 대하여 알아보도록 하겠다.
'Pandas' 카테고리의 다른 글
| [데이터분석] 전국 신규 민간 아파트 분양 가격 동향 분석하기 (2) | 2022.11.07 |
|---|---|
| [Jupyter Notebook] 주피터노트북 목차 활성화 (2) | 2022.11.07 |
| [Pandas] Numpy 배열 인덱싱/슬라이싱 (0) | 2022.11.02 |
| [Pandas] Numpy - matplotlib, seaborn를 이용한 자료 시각화 (2) | 2022.11.01 |
| [Pandas] Numpy - np.zeros, ones, full, eye, random 알아보기 (0) | 2022.11.01 |




댓글